In Kubernetes, scheduling refers to making sure that Pods are matched to Nodes so that the kubelet can run them. Preemption is the process of terminating Pods with lower Priority so that Pods with higher Priority can schedule on Nodes. Eviction is the process of proactively terminating one or more Pods on resource-starved Nodes.
In Kubernetes, scheduling refers to making sure that Pods
are matched to Nodes so that the
kubelet can run them. Preemption
is the process of terminating Pods with lower Priority
so that Pods with higher Priority can schedule on Nodes. Eviction is the process
of terminating one or more Pods on Nodes.
Pod disruption is the process by which Pods on Nodes are terminated either voluntarily or involuntarily.
Voluntary disruptions are started intentionally by application owners or cluster administrators. Involuntary disruptions are unintentional and can be triggered by unavoidable issues like Nodes running out of resources, or by accidental deletions.
In Kubernetes, scheduling refers to making sure that Pods
are matched to Nodes so that
Kubelet can run them.
Scheduling overview
A scheduler watches for newly created Pods that have no Node assigned. For
every Pod that the scheduler discovers, the scheduler becomes responsible
for finding the best Node for that Pod to run on. The scheduler reaches
this placement decision taking into account the scheduling principles
described below.
If you want to understand why Pods are placed onto a particular Node,
or if you're planning to implement a custom scheduler yourself, this
page will help you learn about scheduling.
kube-scheduler
kube-scheduler
is the default scheduler for Kubernetes and runs as part of the
control plane.
kube-scheduler is designed so that, if you want and need to, you can
write your own scheduling component and use that instead.
For every newly created pod or other unscheduled pods, kube-scheduler
selects an optimal node for them to run on. However, every container in
pods has different requirements for resources and every pod also has
different requirements. Therefore, existing nodes need to be filtered
according to the specific scheduling requirements.
In a cluster, Nodes that meet the scheduling requirements for a Pod
are called feasible nodes. If none of the nodes are suitable, the pod
remains unscheduled until the scheduler is able to place it.
The scheduler finds feasible Nodes for a Pod and then runs a set of
functions to score the feasible Nodes and picks a Node with the highest
score among the feasible ones to run the Pod. The scheduler then notifies
the API server about this decision in a process called binding.
Factors that need taken into account for scheduling decisions include
individual and collective resource requirements, hardware / software /
policy constraints, affinity and anti-affinity specifications, data
locality, inter-workload interference, and so on.
Node selection in kube-scheduler
kube-scheduler selects a node for the pod in a 2-step operation:
Filtering
Scoring
The filtering step finds the set of Nodes where it's feasible to
schedule the Pod. For example, the PodFitsResources filter checks whether a
candidate Node has enough available resource to meet a Pod's specific
resource requests. After this step, the node list contains any suitable
Nodes; often, there will be more than one. If the list is empty, that
Pod isn't (yet) schedulable.
In the scoring step, the scheduler ranks the remaining nodes to choose
the most suitable Pod placement. The scheduler assigns a score to each Node
that survived filtering, basing this score on the active scoring rules.
Finally, kube-scheduler assigns the Pod to the Node with the highest ranking.
If there is more than one node with equal scores, kube-scheduler selects
one of these at random.
There are two supported ways to configure the filtering and scoring behavior
of the scheduler:
Scheduling Policies allow you to configure Predicates for filtering and Priorities for scoring.
Scheduling Profiles allow you to configure Plugins that implement different scheduling stages, including: QueueSort, Filter, Score, Bind, Reserve, Permit, and others. You can also configure the kube-scheduler to run different profiles.
You can constrain a Pod so that it can only run on particular set of
Node(s).
There are several ways to do this and the recommended approaches all use
label selectors to facilitate the selection.
Generally such constraints are unnecessary, as the scheduler will automatically do a reasonable placement
(e.g. spread your pods across nodes so as not place the pod on a node with insufficient free resources, etc.)
but there are some circumstances where you may want to control which node the pod deploys to - for example to ensure
that a pod ends up on a machine with an SSD attached to it, or to co-locate pods from two different
services that communicate a lot into the same availability zone.
nodeSelector
nodeSelector is the simplest recommended form of node selection constraint.
nodeSelector is a field of PodSpec. It specifies a map of key-value pairs. For the pod to be eligible
to run on a node, the node must have each of the indicated key-value pairs as labels (it can have
additional labels as well). The most common usage is one key-value pair.
Let's walk through an example of how to use nodeSelector.
Step Zero: Prerequisites
This example assumes that you have a basic understanding of Kubernetes pods and that you have set up a Kubernetes cluster.
Step One: Attach label to the node
Run kubectl get nodes to get the names of your cluster's nodes. Pick out the one that you want to add a label to, and then run kubectl label nodes <node-name> <label-key>=<label-value> to add a label to the node you've chosen. For example, if my node name is 'kubernetes-foo-node-1.c.a-robinson.internal' and my desired label is 'disktype=ssd', then I can run kubectl label nodes kubernetes-foo-node-1.c.a-robinson.internal disktype=ssd.
You can verify that it worked by re-running kubectl get nodes --show-labels and checking that the node now has a label. You can also use kubectl describe node "nodename" to see the full list of labels of the given node.
Step Two: Add a nodeSelector field to your pod configuration
Take whatever pod config file you want to run, and add a nodeSelector section to it, like this. For example, if this is my pod config:
When you then run kubectl apply -f https://k8s.io/examples/pods/pod-nginx.yaml,
the Pod will get scheduled on the node that you attached the label to. You can
verify that it worked by running kubectl get pods -o wide and looking at the
"NODE" that the Pod was assigned to.
Note: The value of these labels is cloud provider specific and is not guaranteed to be reliable.
For example, the value of kubernetes.io/hostname may be the same as the Node name in some environments
and a different value in other environments.
Node isolation/restriction
Adding labels to Node objects allows targeting pods to specific nodes or groups of nodes.
This can be used to ensure specific pods only run on nodes with certain isolation, security, or regulatory properties.
When using labels for this purpose, choosing label keys that cannot be modified by the kubelet process on the node is strongly recommended.
This prevents a compromised node from using its kubelet credential to set those labels on its own Node object,
and influencing the scheduler to schedule workloads to the compromised node.
The NodeRestriction admission plugin prevents kubelets from setting or modifying labels with a node-restriction.kubernetes.io/ prefix.
To make use of that label prefix for node isolation:
Add labels under the node-restriction.kubernetes.io/ prefix to your Node objects, and use those labels in your node selectors.
For example, example.com.node-restriction.kubernetes.io/fips=true or example.com.node-restriction.kubernetes.io/pci-dss=true.
Affinity and anti-affinity
nodeSelector provides a very simple way to constrain pods to nodes with particular labels. The affinity/anti-affinity
feature, greatly expands the types of constraints you can express. The key enhancements are
The affinity/anti-affinity language is more expressive. The language offers more matching rules
besides exact matches created with a logical AND operation;
you can indicate that the rule is "soft"/"preference" rather than a hard requirement, so if the scheduler
can't satisfy it, the pod will still be scheduled;
you can constrain against labels on other pods running on the node (or other topological domain),
rather than against labels on the node itself, which allows rules about which pods can and cannot be co-located
The affinity feature consists of two types of affinity, "node affinity" and "inter-pod affinity/anti-affinity".
Node affinity is like the existing nodeSelector (but with the first two benefits listed above),
while inter-pod affinity/anti-affinity constrains against pod labels rather than node labels, as
described in the third item listed above, in addition to having the first and second properties listed above.
Node affinity
Node affinity is conceptually similar to nodeSelector -- it allows you to constrain which nodes your
pod is eligible to be scheduled on, based on labels on the node.
There are currently two types of node affinity, called requiredDuringSchedulingIgnoredDuringExecution and
preferredDuringSchedulingIgnoredDuringExecution. You can think of them as "hard" and "soft" respectively,
in the sense that the former specifies rules that must be met for a pod to be scheduled onto a node (similar to
nodeSelector but using a more expressive syntax), while the latter specifies preferences that the scheduler
will try to enforce but will not guarantee. The "IgnoredDuringExecution" part of the names means that, similar
to how nodeSelector works, if labels on a node change at runtime such that the affinity rules on a pod are no longer
met, the pod continues to run on the node. In the future we plan to offer
requiredDuringSchedulingRequiredDuringExecution which will be identical to requiredDuringSchedulingIgnoredDuringExecution
except that it will evict pods from nodes that cease to satisfy the pods' node affinity requirements.
Thus an example of requiredDuringSchedulingIgnoredDuringExecution would be "only run the pod on nodes with Intel CPUs"
and an example preferredDuringSchedulingIgnoredDuringExecution would be "try to run this set of pods in failure
zone XYZ, but if it's not possible, then allow some to run elsewhere".
Node affinity is specified as field nodeAffinity of field affinity in the PodSpec.
Here's an example of a pod that uses node affinity:
This node affinity rule says the pod can only be placed on a node with a label whose key is
kubernetes.io/e2e-az-name and whose value is either e2e-az1 or e2e-az2. In addition,
among nodes that meet that criteria, nodes with a label whose key is another-node-label-key and whose
value is another-node-label-value should be preferred.
You can see the operator In being used in the example. The new node affinity syntax supports the following operators: In, NotIn, Exists, DoesNotExist, Gt, Lt.
You can use NotIn and DoesNotExist to achieve node anti-affinity behavior, or use
node taints to repel pods from specific nodes.
If you specify both nodeSelector and nodeAffinity, both must be satisfied for the pod
to be scheduled onto a candidate node.
If you specify multiple nodeSelectorTerms associated with nodeAffinity types, then the pod can be scheduled onto a node if one of thenodeSelectorTerms can be satisfied.
If you specify multiple matchExpressions associated with nodeSelectorTerms, then the pod can be scheduled onto a node only if allmatchExpressions is satisfied.
If you remove or change the label of the node where the pod is scheduled, the pod won't be removed. In other words, the affinity selection works only at the time of scheduling the pod.
The weight field in preferredDuringSchedulingIgnoredDuringExecution is in the range 1-100. For each node that meets all of the scheduling requirements (resource request, RequiredDuringScheduling affinity expressions, etc.), the scheduler will compute a sum by iterating through the elements of this field and adding "weight" to the sum if the node matches the corresponding MatchExpressions. This score is then combined with the scores of other priority functions for the node. The node(s) with the highest total score are the most preferred.
Node affinity per scheduling profile
FEATURE STATE:Kubernetes v1.20 [beta]
When configuring multiple scheduling profiles, you can associate
a profile with a Node affinity, which is useful if a profile only applies to a specific set of Nodes.
To do so, add an addedAffinity to the args of the NodeAffinity plugin
in the scheduler configuration. For example:
The addedAffinity is applied to all Pods that set .spec.schedulerName to foo-scheduler, in addition to the
NodeAffinity specified in the PodSpec.
That is, in order to match the Pod, Nodes need to satisfy addedAffinity and the Pod's .spec.NodeAffinity.
Since the addedAffinity is not visible to end users, its behavior might be unexpected to them. We
recommend to use node labels that have clear correlation with the profile's scheduler name.
Note: The DaemonSet controller, which creates Pods for DaemonSets
is not aware of scheduling profiles. For this reason, it is recommended that you keep a scheduler profile, such as the
default-scheduler, without any addedAffinity. Then, the Daemonset's Pod template should use this scheduler name.
Otherwise, some Pods created by the Daemonset controller might remain unschedulable.
Inter-pod affinity and anti-affinity
Inter-pod affinity and anti-affinity allow you to constrain which nodes your pod is eligible to be scheduled based on
labels on pods that are already running on the node rather than based on labels on nodes. The rules are of the form
"this pod should (or, in the case of anti-affinity, should not) run in an X if that X is already running one or more pods that meet rule Y".
Y is expressed as a LabelSelector with an optional associated list of namespaces; unlike nodes, because pods are namespaced
(and therefore the labels on pods are implicitly namespaced),
a label selector over pod labels must specify which namespaces the selector should apply to. Conceptually X is a topology domain
like node, rack, cloud provider zone, cloud provider region, etc. You express it using a topologyKey which is the
key for the node label that the system uses to denote such a topology domain; for example, see the label keys listed above
in the section Interlude: built-in node labels.
Note: Inter-pod affinity and anti-affinity require substantial amount of
processing which can slow down scheduling in large clusters significantly. We do
not recommend using them in clusters larger than several hundred nodes.
Note: Pod anti-affinity requires nodes to be consistently labelled, in other words every node in the cluster must have an appropriate label matching topologyKey. If some or all nodes are missing the specified topologyKey label, it can lead to unintended behavior.
As with node affinity, there are currently two types of pod affinity and anti-affinity, called requiredDuringSchedulingIgnoredDuringExecution and
preferredDuringSchedulingIgnoredDuringExecution which denote "hard" vs. "soft" requirements.
See the description in the node affinity section earlier.
An example of requiredDuringSchedulingIgnoredDuringExecution affinity would be "co-locate the pods of service A and service B
in the same zone, since they communicate a lot with each other"
and an example preferredDuringSchedulingIgnoredDuringExecution anti-affinity would be "spread the pods from this service across zones"
(a hard requirement wouldn't make sense, since you probably have more pods than zones).
Inter-pod affinity is specified as field podAffinity of field affinity in the PodSpec.
And inter-pod anti-affinity is specified as field podAntiAffinity of field affinity in the PodSpec.
The affinity on this pod defines one pod affinity rule and one pod anti-affinity rule. In this example, the
podAffinity is requiredDuringSchedulingIgnoredDuringExecution
while the podAntiAffinity is preferredDuringSchedulingIgnoredDuringExecution. The
pod affinity rule says that the pod can be scheduled onto a node only if that node is in the same zone
as at least one already-running pod that has a label with key "security" and value "S1". (More precisely, the pod is eligible to run
on node N if node N has a label with key topology.kubernetes.io/zone and some value V
such that there is at least one node in the cluster with key topology.kubernetes.io/zone and
value V that is running a pod that has a label with key "security" and value "S1".) The pod anti-affinity
rule says that the pod should not be scheduled onto a node if that node is in the same zone as a pod with
label having key "security" and value "S2". See the
design doc
for many more examples of pod affinity and anti-affinity, both the requiredDuringSchedulingIgnoredDuringExecution
flavor and the preferredDuringSchedulingIgnoredDuringExecution flavor.
The legal operators for pod affinity and anti-affinity are In, NotIn, Exists, DoesNotExist.
In principle, the topologyKey can be any legal label-key. However,
for performance and security reasons, there are some constraints on topologyKey:
For pod affinity, empty topologyKey is not allowed in both requiredDuringSchedulingIgnoredDuringExecution
and preferredDuringSchedulingIgnoredDuringExecution.
For pod anti-affinity, empty topologyKey is also not allowed in both requiredDuringSchedulingIgnoredDuringExecution
and preferredDuringSchedulingIgnoredDuringExecution.
For requiredDuringSchedulingIgnoredDuringExecution pod anti-affinity, the admission controller LimitPodHardAntiAffinityTopology was introduced to limit topologyKey to kubernetes.io/hostname. If you want to make it available for custom topologies, you may modify the admission controller, or disable it.
Except for the above cases, the topologyKey can be any legal label-key.
In addition to labelSelector and topologyKey, you can optionally specify a list namespaces
of namespaces which the labelSelector should match against (this goes at the same level of the definition as labelSelector and topologyKey).
If omitted or empty, it defaults to the namespace of the pod where the affinity/anti-affinity definition appears.
All matchExpressions associated with requiredDuringSchedulingIgnoredDuringExecution affinity and anti-affinity
must be satisfied for the pod to be scheduled onto a node.
Namespace selector
FEATURE STATE:Kubernetes v1.21 [alpha]
Users can also select matching namespaces using namespaceSelector, which is a label query over the set of namespaces.
The affinity term is applied to the union of the namespaces selected by namespaceSelector and the ones listed in the namespaces field.
Note that an empty namespaceSelector ({}) matches all namespaces, while a null or empty namespaces list and
null namespaceSelector means "this pod's namespace".
This feature is alpha and disabled by default. You can enable it by setting the
feature gatePodAffinityNamespaceSelector in both kube-apiserver and kube-scheduler.
More Practical Use-cases
Interpod Affinity and AntiAffinity can be even more useful when they are used with higher
level collections such as ReplicaSets, StatefulSets, Deployments, etc. One can easily configure that a set of workloads should
be co-located in the same defined topology, eg., the same node.
Always co-located in the same node
In a three node cluster, a web application has in-memory cache such as redis. We want the web-servers to be co-located with the cache as much as possible.
Here is the yaml snippet of a simple redis deployment with three replicas and selector label app=store. The deployment has PodAntiAffinity configured to ensure the scheduler does not co-locate replicas on a single node.
The below yaml snippet of the webserver deployment has podAntiAffinity and podAffinity configured. This informs the scheduler that all its replicas are to be co-located with pods that have selector label app=store. This will also ensure that each web-server replica does not co-locate on a single node.
The above example uses PodAntiAffinity rule with topologyKey: "kubernetes.io/hostname" to deploy the redis cluster so that
no two instances are located on the same host.
See ZooKeeper tutorial
for an example of a StatefulSet configured with anti-affinity for high availability, using the same technique.
nodeName
nodeName is the simplest form of node selection constraint, but due
to its limitations it is typically not used. nodeName is a field of
PodSpec. If it is non-empty, the scheduler ignores the pod and the
kubelet running on the named node tries to run the pod. Thus, if
nodeName is provided in the PodSpec, it takes precedence over the
above methods for node selection.
Some of the limitations of using nodeName to select nodes are:
If the named node does not exist, the pod will not be run, and in
some cases may be automatically deleted.
If the named node does not have the resources to accommodate the
pod, the pod will fail and its reason will indicate why,
for example OutOfmemory or OutOfcpu.
Node names in cloud environments are not always predictable or
stable.
Here is an example of a pod config file using the nodeName field:
Once a Pod is assigned to a Node, the kubelet runs the Pod and allocates node-local resources.
The topology manager can take part in node-level
resource allocation decisions.
3 - Pod Overhead
FEATURE STATE:Kubernetes v1.18 [beta]
When you run a Pod on a Node, the Pod itself takes an amount of system resources. These
resources are additional to the resources needed to run the container(s) inside the Pod.
Pod Overhead is a feature for accounting for the resources consumed by the Pod infrastructure
on top of the container requests & limits.
In Kubernetes, the Pod's overhead is set at
admission
time according to the overhead associated with the Pod's
RuntimeClass.
When Pod Overhead is enabled, the overhead is considered in addition to the sum of container
resource requests when scheduling a Pod. Similarly, the kubelet will include the Pod overhead when sizing
the Pod cgroup, and when carrying out Pod eviction ranking.
Enabling Pod Overhead
You need to make sure that the PodOverheadfeature gate is enabled (it is on by default as of 1.18)
across your cluster, and a RuntimeClass is utilized which defines the overhead field.
Usage example
To use the PodOverhead feature, you need a RuntimeClass that defines the overhead field. As
an example, you could use the following RuntimeClass definition with a virtualizing container runtime
that uses around 120MiB per Pod for the virtual machine and the guest OS:
Workloads which are created which specify the kata-fc RuntimeClass handler will take the memory and
cpu overheads into account for resource quota calculations, node scheduling, as well as Pod cgroup sizing.
Consider running the given example workload, test-pod:
At admission time the RuntimeClass admission controller
updates the workload's PodSpec to include the overhead as described in the RuntimeClass. If the PodSpec already has this field defined,
the Pod will be rejected. In the given example, since only the RuntimeClass name is specified, the admission controller mutates the Pod
to include an overhead.
After the RuntimeClass admission controller, you can check the updated PodSpec:
kubectl get pod test-pod -o jsonpath='{.spec.overhead}'
The output is:
map[cpu:250m memory:120Mi]
If a ResourceQuota is defined, the sum of container requests as well as the
overhead field are counted.
When the kube-scheduler is deciding which node should run a new Pod, the scheduler considers that Pod's
overhead as well as the sum of container requests for that Pod. For this example, the scheduler adds the
requests and the overhead, then looks for a node that has 2.25 CPU and 320 MiB of memory available.
Once a Pod is scheduled to a node, the kubelet on that node creates a new cgroup
for the Pod. It is within this pod that the underlying container runtime will create containers.
If the resource has a limit defined for each container (Guaranteed QoS or Bustrable QoS with limits defined),
the kubelet will set an upper limit for the pod cgroup associated with that resource (cpu.cfs_quota_us for CPU
and memory.limit_in_bytes memory). This upper limit is based on the sum of the container limits plus the overhead
defined in the PodSpec.
For CPU, if the Pod is Guaranteed or Burstable QoS, the kubelet will set cpu.shares based on the sum of container
requests plus the overhead defined in the PodSpec.
Looking at our example, verify the container requests for the workload:
kubectl get pod test-pod -o jsonpath='{.spec.containers[*].resources.limits}'
The total container requests are 2000m CPU and 200MiB of memory:
The output shows 2250m CPU and 320MiB of memory are requested, which includes PodOverhead:
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default test-pod 2250m (56%) 2250m (56%) 320Mi (1%) 320Mi (1%) 36m
Verify Pod cgroup limits
Check the Pod's memory cgroups on the node where the workload is running. In the following example, crictl
is used on the node, which provides a CLI for CRI-compatible container runtimes. This is an
advanced example to show PodOverhead behavior, and it is not expected that users should need to check
cgroups directly on the node.
First, on the particular node, determine the Pod identifier:
# Run this on the node where the Pod is scheduledPOD_ID="$(sudo crictl pods --name test-pod -q)"
From this, you can determine the cgroup path for the Pod:
# Run this on the node where the Pod is scheduled
sudo crictl inspectp -o=json $POD_ID | grep cgroupsPath
The resulting cgroup path includes the Pod's pause container. The Pod level cgroup is one directory above.
In this specific case, the pod cgroup path is kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2. Verify the Pod level cgroup setting for memory:
# Run this on the node where the Pod is scheduled.# Also, change the name of the cgroup to match the cgroup allocated for your pod.
cat /sys/fs/cgroup/memory/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/memory.limit_in_bytes
This is 320 MiB, as expected:
335544320
Observability
A kube_pod_overhead metric is available in kube-state-metrics
to help identify when PodOverhead is being utilized and to help observe stability of workloads
running with a defined Overhead. This functionality is not available in the 1.9 release of
kube-state-metrics, but is expected in a following release. Users will need to build kube-state-metrics
from source in the meantime.
Node affinity
is a property of Pods that attracts them to
a set of nodes (either as a preference or a
hard requirement). Taints are the opposite -- they allow a node to repel a set of pods.
Tolerations are applied to pods, and allow (but do not require) the pods to schedule
onto nodes with matching taints.
Taints and tolerations work together to ensure that pods are not scheduled
onto inappropriate nodes. One or more taints are applied to a node; this
marks that the node should not accept any pods that do not tolerate the taints.
Concepts
You add a taint to a node using kubectl taint.
For example,
kubectl taint nodes node1 key1=value1:NoSchedule
places a taint on node node1. The taint has key key1, value value1, and taint effect NoSchedule.
This means that no pod will be able to schedule onto node1 unless it has a matching toleration.
To remove the taint added by the command above, you can run:
kubectl taint nodes node1 key1=value1:NoSchedule-
You specify a toleration for a pod in the PodSpec. Both of the following tolerations "match" the
taint created by the kubectl taint line above, and thus a pod with either toleration would be able
to schedule onto node1:
A toleration "matches" a taint if the keys are the same and the effects are the same, and:
the operator is Exists (in which case no value should be specified), or
the operator is Equal and the values are equal.
Note:
There are two special cases:
An empty key with operator Exists matches all keys, values and effects which means this
will tolerate everything.
An empty effect matches all effects with key key1.
The above example used effect of NoSchedule. Alternatively, you can use effect of PreferNoSchedule.
This is a "preference" or "soft" version of NoSchedule -- the system will try to avoid placing a
pod that does not tolerate the taint on the node, but it is not required. The third kind of effect is
NoExecute, described later.
You can put multiple taints on the same node and multiple tolerations on the same pod.
The way Kubernetes processes multiple taints and tolerations is like a filter: start
with all of a node's taints, then ignore the ones for which the pod has a matching toleration; the
remaining un-ignored taints have the indicated effects on the pod. In particular,
if there is at least one un-ignored taint with effect NoSchedule then Kubernetes will not schedule
the pod onto that node
if there is no un-ignored taint with effect NoSchedule but there is at least one un-ignored taint with
effect PreferNoSchedule then Kubernetes will try to not schedule the pod onto the node
if there is at least one un-ignored taint with effect NoExecute then the pod will be evicted from
the node (if it is already running on the node), and will not be
scheduled onto the node (if it is not yet running on the node).
In this case, the pod will not be able to schedule onto the node, because there is no
toleration matching the third taint. But it will be able to continue running if it is
already running on the node when the taint is added, because the third taint is the only
one of the three that is not tolerated by the pod.
Normally, if a taint with effect NoExecute is added to a node, then any pods that do
not tolerate the taint will be evicted immediately, and pods that do tolerate the
taint will never be evicted. However, a toleration with NoExecute effect can specify
an optional tolerationSeconds field that dictates how long the pod will stay bound
to the node after the taint is added. For example,
means that if this pod is running and a matching taint is added to the node, then
the pod will stay bound to the node for 3600 seconds, and then be evicted. If the
taint is removed before that time, the pod will not be evicted.
Example Use Cases
Taints and tolerations are a flexible way to steer pods away from nodes or evict
pods that shouldn't be running. A few of the use cases are
Dedicated Nodes: If you want to dedicate a set of nodes for exclusive use by
a particular set of users, you can add a taint to those nodes (say,
kubectl taint nodes nodename dedicated=groupName:NoSchedule) and then add a corresponding
toleration to their pods (this would be done most easily by writing a custom
admission controller).
The pods with the tolerations will then be allowed to use the tainted (dedicated) nodes as
well as any other nodes in the cluster. If you want to dedicate the nodes to them and
ensure they only use the dedicated nodes, then you should additionally add a label similar
to the taint to the same set of nodes (e.g. dedicated=groupName), and the admission
controller should additionally add a node affinity to require that the pods can only schedule
onto nodes labeled with dedicated=groupName.
Nodes with Special Hardware: In a cluster where a small subset of nodes have specialized
hardware (for example GPUs), it is desirable to keep pods that don't need the specialized
hardware off of those nodes, thus leaving room for later-arriving pods that do need the
specialized hardware. This can be done by tainting the nodes that have the specialized
hardware (e.g. kubectl taint nodes nodename special=true:NoSchedule or
kubectl taint nodes nodename special=true:PreferNoSchedule) and adding a corresponding
toleration to pods that use the special hardware. As in the dedicated nodes use case,
it is probably easiest to apply the tolerations using a custom
admission controller.
For example, it is recommended to use Extended
Resources
to represent the special hardware, taint your special hardware nodes with the
extended resource name and run the
ExtendedResourceToleration
admission controller. Now, because the nodes are tainted, no pods without the
toleration will schedule on them. But when you submit a pod that requests the
extended resource, the ExtendedResourceToleration admission controller will
automatically add the correct toleration to the pod and that pod will schedule
on the special hardware nodes. This will make sure that these special hardware
nodes are dedicated for pods requesting such hardware and you don't have to
manually add tolerations to your pods.
Taint based Evictions: A per-pod-configurable eviction behavior
when there are node problems, which is described in the next section.
Taint based Evictions
FEATURE STATE:Kubernetes v1.18 [stable]
The NoExecute taint effect, mentioned above, affects pods that are already
running on the node as follows
pods that do not tolerate the taint are evicted immediately
pods that tolerate the taint without specifying tolerationSeconds in
their toleration specification remain bound forever
pods that tolerate the taint with a specified tolerationSeconds remain
bound for the specified amount of time
The node controller automatically taints a Node when certain conditions
are true. The following taints are built in:
node.kubernetes.io/not-ready: Node is not ready. This corresponds to
the NodeCondition Ready being "False".
node.kubernetes.io/unreachable: Node is unreachable from the node
controller. This corresponds to the NodeCondition Ready being "Unknown".
node.kubernetes.io/memory-pressure: Node has memory pressure.
node.kubernetes.io/disk-pressure: Node has disk pressure.
node.kubernetes.io/pid-pressure: Node has PID pressure.
node.kubernetes.io/network-unavailable: Node's network is unavailable.
node.kubernetes.io/unschedulable: Node is unschedulable.
node.cloudprovider.kubernetes.io/uninitialized: When the kubelet is started
with "external" cloud provider, this taint is set on a node to mark it
as unusable. After a controller from the cloud-controller-manager initializes
this node, the kubelet removes this taint.
In case a node is to be evicted, the node controller or the kubelet adds relevant taints
with NoExecute effect. If the fault condition returns to normal the kubelet or node
controller can remove the relevant taint(s).
Note: The control plane limits the rate of adding node new taints to nodes. This rate limiting
manages the number of evictions that are triggered when many nodes become unreachable at
once (for example: if there is a network disruption).
You can specify tolerationSeconds for a Pod to define how long that Pod stays bound
to a failing or unresponsive Node.
For example, you might want to keep an application with a lot of local state
bound to node for a long time in the event of network partition, hoping
that the partition will recover and thus the pod eviction can be avoided.
The toleration you set for that Pod might look like:
Kubernetes automatically adds a toleration for
node.kubernetes.io/not-ready and node.kubernetes.io/unreachable
with tolerationSeconds=300,
unless you, or a controller, set those tolerations explicitly.
These automatically-added tolerations mean that Pods remain bound to
Nodes for 5 minutes after one of these problems is detected.
DaemonSet pods are created with
NoExecute tolerations for the following taints with no tolerationSeconds:
node.kubernetes.io/unreachable
node.kubernetes.io/not-ready
This ensures that DaemonSet pods are never evicted due to these problems.
Taint Nodes by Condition
The control plane, using the node controller,
automatically creates taints with a NoSchedule effect for node conditions.
The scheduler checks taints, not node conditions, when it makes scheduling
decisions. This ensures that node conditions don't directly affect scheduling.
For example, if the DiskPressure node condition is active, the control plane
adds the node.kubernetes.io/disk-pressure taint and does not schedule new pods
onto the affected node. If the MemoryPressure node condition is active, the
control plane adds the node.kubernetes.io/memory-pressure taint.
You can ignore node conditions for newly created pods by adding the corresponding
Pod tolerations. The control plane also adds the node.kubernetes.io/memory-pressure
toleration on pods that have a QoS class
other than BestEffort. This is because Kubernetes treats pods in the Guaranteed
or Burstable QoS classes (even pods with no memory request set) as if they are
able to cope with memory pressure, while new BestEffort pods are not scheduled
onto the affected node.
The DaemonSet controller automatically adds the following NoSchedule
tolerations to all daemons, to prevent DaemonSets from breaking.
Pods can have priority. Priority indicates the
importance of a Pod relative to other Pods. If a Pod cannot be scheduled, the
scheduler tries to preempt (evict) lower priority Pods to make scheduling of the
pending Pod possible.
Warning:
In a cluster where not all users are trusted, a malicious user could create Pods
at the highest possible priorities, causing other Pods to be evicted/not get
scheduled.
An administrator can use ResourceQuota to prevent users from creating pods at
high priorities.
Create Pods withpriorityClassName set to one of the added
PriorityClasses. Of course you do not need to create the Pods directly;
normally you would add priorityClassName to the Pod template of a
collection object like a Deployment.
Keep reading for more information about these steps.
A PriorityClass is a non-namespaced object that defines a mapping from a
priority class name to the integer value of the priority. The name is specified
in the name field of the PriorityClass object's metadata. The value is
specified in the required value field. The higher the value, the higher the
priority.
The name of a PriorityClass object must be a valid
DNS subdomain name,
and it cannot be prefixed with system-.
A PriorityClass object can have any 32-bit integer value smaller than or equal
to 1 billion. Larger numbers are reserved for critical system Pods that should
not normally be preempted or evicted. A cluster admin should create one
PriorityClass object for each such mapping that they want.
PriorityClass also has two optional fields: globalDefault and description.
The globalDefault field indicates that the value of this PriorityClass should
be used for Pods without a priorityClassName. Only one PriorityClass with
globalDefault set to true can exist in the system. If there is no
PriorityClass with globalDefault set, the priority of Pods with no
priorityClassName is zero.
The description field is an arbitrary string. It is meant to tell users of the
cluster when they should use this PriorityClass.
Notes about PodPriority and existing clusters
If you upgrade an existing cluster without this feature, the priority
of your existing Pods is effectively zero.
Addition of a PriorityClass with globalDefault set to true does not
change the priorities of existing Pods. The value of such a PriorityClass is
used only for Pods created after the PriorityClass is added.
If you delete a PriorityClass, existing Pods that use the name of the
deleted PriorityClass remain unchanged, but you cannot create more Pods that
use the name of the deleted PriorityClass.
Example PriorityClass
apiVersion:scheduling.k8s.io/v1kind:PriorityClassmetadata:name:high-priorityvalue:1000000globalDefault:falsedescription:"This priority class should be used for XYZ service pods only."
Non-preempting PriorityClass
FEATURE STATE:Kubernetes v1.19 [beta]
Pods with PreemptionPolicy: Never will be placed in the scheduling queue
ahead of lower-priority pods,
but they cannot preempt other pods.
A non-preempting pod waiting to be scheduled will stay in the scheduling queue,
until sufficient resources are free,
and it can be scheduled.
Non-preempting pods,
like other pods,
are subject to scheduler back-off.
This means that if the scheduler tries these pods and they cannot be scheduled,
they will be retried with lower frequency,
allowing other pods with lower priority to be scheduled before them.
Non-preempting pods may still be preempted by other,
high-priority pods.
PreemptionPolicy defaults to PreemptLowerPriority,
which will allow pods of that PriorityClass to preempt lower-priority pods
(as is existing default behavior).
If PreemptionPolicy is set to Never,
pods in that PriorityClass will be non-preempting.
An example use case is for data science workloads.
A user may submit a job that they want to be prioritized above other workloads,
but do not wish to discard existing work by preempting running pods.
The high priority job with PreemptionPolicy: Never will be scheduled
ahead of other queued pods,
as soon as sufficient cluster resources "naturally" become free.
Example Non-preempting PriorityClass
apiVersion:scheduling.k8s.io/v1kind:PriorityClassmetadata:name:high-priority-nonpreemptingvalue:1000000preemptionPolicy:NeverglobalDefault:falsedescription:"This priority class will not cause other pods to be preempted."
Pod priority
After you have one or more PriorityClasses, you can create Pods that specify one
of those PriorityClass names in their specifications. The priority admission
controller uses the priorityClassName field and populates the integer value of
the priority. If the priority class is not found, the Pod is rejected.
The following YAML is an example of a Pod configuration that uses the
PriorityClass created in the preceding example. The priority admission
controller checks the specification and resolves the priority of the Pod to
1000000.
When Pod priority is enabled, the scheduler orders pending Pods by
their priority and a pending Pod is placed ahead of other pending Pods
with lower priority in the scheduling queue. As a result, the higher
priority Pod may be scheduled sooner than Pods with lower priority if
its scheduling requirements are met. If such Pod cannot be scheduled,
scheduler will continue and tries to schedule other lower priority Pods.
Preemption
When Pods are created, they go to a queue and wait to be scheduled. The
scheduler picks a Pod from the queue and tries to schedule it on a Node. If no
Node is found that satisfies all the specified requirements of the Pod,
preemption logic is triggered for the pending Pod. Let's call the pending Pod P.
Preemption logic tries to find a Node where removal of one or more Pods with
lower priority than P would enable P to be scheduled on that Node. If such a
Node is found, one or more lower priority Pods get evicted from the Node. After
the Pods are gone, P can be scheduled on the Node.
User exposed information
When Pod P preempts one or more Pods on Node N, nominatedNodeName field of Pod
P's status is set to the name of Node N. This field helps scheduler track
resources reserved for Pod P and also gives users information about preemptions
in their clusters.
Please note that Pod P is not necessarily scheduled to the "nominated Node".
After victim Pods are preempted, they get their graceful termination period. If
another node becomes available while scheduler is waiting for the victim Pods to
terminate, scheduler will use the other node to schedule Pod P. As a result
nominatedNodeName and nodeName of Pod spec are not always the same. Also, if
scheduler preempts Pods on Node N, but then a higher priority Pod than Pod P
arrives, scheduler may give Node N to the new higher priority Pod. In such a
case, scheduler clears nominatedNodeName of Pod P. By doing this, scheduler
makes Pod P eligible to preempt Pods on another Node.
Limitations of preemption
Graceful termination of preemption victims
When Pods are preempted, the victims get their
graceful termination period.
They have that much time to finish their work and exit. If they don't, they are
killed. This graceful termination period creates a time gap between the point
that the scheduler preempts Pods and the time when the pending Pod (P) can be
scheduled on the Node (N). In the meantime, the scheduler keeps scheduling other
pending Pods. As victims exit or get terminated, the scheduler tries to schedule
Pods in the pending queue. Therefore, there is usually a time gap between the
point that scheduler preempts victims and the time that Pod P is scheduled. In
order to minimize this gap, one can set graceful termination period of lower
priority Pods to zero or a small number.
PodDisruptionBudget is supported, but not guaranteed
A PodDisruptionBudget (PDB)
allows application owners to limit the number of Pods of a replicated application
that are down simultaneously from voluntary disruptions. Kubernetes supports
PDB when preempting Pods, but respecting PDB is best effort. The scheduler tries
to find victims whose PDB are not violated by preemption, but if no such victims
are found, preemption will still happen, and lower priority Pods will be removed
despite their PDBs being violated.
Inter-Pod affinity on lower-priority Pods
A Node is considered for preemption only when the answer to this question is
yes: "If all the Pods with lower priority than the pending Pod are removed from
the Node, can the pending Pod be scheduled on the Node?"
Note: Preemption does not necessarily remove all lower-priority
Pods. If the pending Pod can be scheduled by removing fewer than all
lower-priority Pods, then only a portion of the lower-priority Pods are removed.
Even so, the answer to the preceding question must be yes. If the answer is no,
the Node is not considered for preemption.
If a pending Pod has inter-pod affinity
to one or more of the lower-priority Pods on the Node, the inter-Pod affinity
rule cannot be satisfied in the absence of those lower-priority Pods. In this case,
the scheduler does not preempt any Pods on the Node. Instead, it looks for another
Node. The scheduler might find a suitable Node or it might not. There is no
guarantee that the pending Pod can be scheduled.
Our recommended solution for this problem is to create inter-Pod affinity only
towards equal or higher priority Pods.
Cross node preemption
Suppose a Node N is being considered for preemption so that a pending Pod P can
be scheduled on N. P might become feasible on N only if a Pod on another Node is
preempted. Here's an example:
Pod P is being considered for Node N.
Pod Q is running on another Node in the same Zone as Node N.
Pod P has Zone-wide anti-affinity with Pod Q (topologyKey: topology.kubernetes.io/zone).
There are no other cases of anti-affinity between Pod P and other Pods in
the Zone.
In order to schedule Pod P on Node N, Pod Q can be preempted, but scheduler
does not perform cross-node preemption. So, Pod P will be deemed
unschedulable on Node N.
If Pod Q were removed from its Node, the Pod anti-affinity violation would be
gone, and Pod P could possibly be scheduled on Node N.
We may consider adding cross Node preemption in future versions if there is
enough demand and if we find an algorithm with reasonable performance.
Troubleshooting
Pod priority and pre-emption can have unwanted side effects. Here are some
examples of potential problems and ways to deal with them.
Pods are preempted unnecessarily
Preemption removes existing Pods from a cluster under resource pressure to make
room for higher priority pending Pods. If you give high priorities to
certain Pods by mistake, these unintentionally high priority Pods may cause
preemption in your cluster. Pod priority is specified by setting the
priorityClassName field in the Pod's specification. The integer value for
priority is then resolved and populated to the priority field of podSpec.
To address the problem, you can change the priorityClassName for those Pods
to use lower priority classes, or leave that field empty. An empty
priorityClassName is resolved to zero by default.
When a Pod is preempted, there will be events recorded for the preempted Pod.
Preemption should happen only when a cluster does not have enough resources for
a Pod. In such cases, preemption happens only when the priority of the pending
Pod (preemptor) is higher than the victim Pods. Preemption must not happen when
there is no pending Pod, or when the pending Pods have equal or lower priority
than the victims. If preemption happens in such scenarios, please file an issue.
Pods are preempted, but the preemptor is not scheduled
When pods are preempted, they receive their requested graceful termination
period, which is by default 30 seconds. If the victim Pods do not terminate within
this period, they are forcibly terminated. Once all the victims go away, the
preemptor Pod can be scheduled.
While the preemptor Pod is waiting for the victims to go away, a higher priority
Pod may be created that fits on the same Node. In this case, the scheduler will
schedule the higher priority Pod instead of the preemptor.
This is expected behavior: the Pod with the higher priority should take the place
of a Pod with a lower priority.
Higher priority Pods are preempted before lower priority pods
The scheduler tries to find nodes that can run a pending Pod. If no node is
found, the scheduler tries to remove Pods with lower priority from an arbitrary
node in order to make room for the pending pod.
If a node with low priority Pods is not feasible to run the pending Pod, the scheduler
may choose another node with higher priority Pods (compared to the Pods on the
other node) for preemption. The victims must still have lower priority than the
preemptor Pod.
When there are multiple nodes available for preemption, the scheduler tries to
choose the node with a set of Pods with lowest priority. However, if such Pods
have PodDisruptionBudget that would be violated if they are preempted then the
scheduler may choose another node with higher priority Pods.
When multiple nodes exist for preemption and none of the above scenarios apply,
the scheduler chooses a node with the lowest priority.
Interactions between Pod priority and quality of service
Pod priority and QoS class
are two orthogonal features with few interactions and no default restrictions on
setting the priority of a Pod based on its QoS classes. The scheduler's
preemption logic does not consider QoS when choosing preemption targets.
Preemption considers Pod priority and attempts to choose a set of targets with
the lowest priority. Higher-priority Pods are considered for preemption only if
the removal of the lowest priority Pods is not sufficient to allow the scheduler
to schedule the preemptor Pod, or if the lowest priority Pods are protected by
PodDisruptionBudget.
The kubelet uses Priority to determine pod order for node-pressure eviction.
You can use the QoS class to estimate the order in which pods are most likely
to get evicted. The kubelet ranks pods for eviction based on the following factors:
Whether the starved resource usage exceeds requests
kubelet node-pressure eviction does not evict Pods when their
usage does not exceed their requests. If a Pod with lower priority is not
exceeding its requests, it won't be evicted. Another Pod with higher priority
that exceeds its requests may be evicted.
Node-pressure eviction is the process by which the kubelet proactively terminates
pods to reclaim resources on nodes.
The kubelet monitors resources
like CPU, memory, disk space, and filesystem inodes on your cluster's nodes.
When one or more of these resources reach specific consumption levels, the
kubelet can proactively fail one or more pods on the node to reclaim resources
and prevent starvation.
During a node-pressure eviction, the kubelet sets the PodPhase for the
selected pods to Failed. This terminates the pods.
The kubelet does not respect your configured PodDisruptionBudget or the pod's
terminationGracePeriodSeconds. If you use soft eviction thresholds,
the kubelet respects your configured eviction-max-pod-grace-period. If you use
hard eviction thresholds, it uses a 0s grace period for termination.
If the pods are managed by a workload
resource (such as StatefulSet
or Deployment) that
replaces failed pods, the control plane or kube-controller-manager creates new
pods in place of the evicted pods.
Note: The kubelet attempts to reclaim node-level resources
before it terminates end-user pods. For example, it removes unused container
images when disk resources are starved.
The kubelet uses various parameters to make eviction decisions, like the following:
Eviction signals
Eviction thresholds
Monitoring intervals
Eviction signals
Eviction signals are the current state of a particular resource at a specific
point in time. Kubelet uses eviction signals to make eviction decisions by
comparing the signals to eviction thresholds, which are the minimum amount of
the resource that should be available on the node.
In this table, the Description column shows how kubelet gets the value of the
signal. Each signal supports either a percentage or a literal value. Kubelet
calculates the percentage value relative to the total capacity associated with
the signal.
The value for memory.available is derived from the cgroupfs instead of tools
like free -m. This is important because free -m does not work in a
container, and if users use the node
allocatable feature, out of resource decisions
are made local to the end user Pod part of the cgroup hierarchy as well as the
root node. This script
reproduces the same set of steps that the kubelet performs to calculate
memory.available. The kubelet excludes inactive_file (i.e. # of bytes of
file-backed memory on inactive LRU list) from its calculation as it assumes that
memory is reclaimable under pressure.
The kubelet supports the following filesystem partitions:
nodefs: The node's main filesystem, used for local disk volumes, emptyDir,
log storage, and more. For example, nodefs contains /var/lib/kubelet/.
imagefs: An optional filesystem that container runtimes use to store container
images and container writable layers.
Kubelet auto-discovers these filesystems and ignores other filesystems. Kubelet
does not support other configurations.
Note: Some kubelet garbage collection features are deprecated in favor of eviction.
For a list of the deprecated features, see kubelet garbage collection deprecation.
Eviction thresholds
You can specify custom eviction thresholds for the kubelet to use when it makes
eviction decisions.
Eviction thresholds have the form [eviction-signal][operator][quantity], where:
quantity is the eviction threshold amount, such as 1Gi. The value of quantity
must match the quantity representation used by Kubernetes. You can use either
literal values or percentages (%).
For example, if a node has 10Gi of total memory and you want trigger eviction if
the available memory falls below 1Gi, you can define the eviction threshold as
either memory.available<10% or memory.available<1Gi. You cannot use both.
You can configure soft and hard eviction thresholds.
Soft eviction thresholds
A soft eviction threshold pairs an eviction threshold with a required
administrator-specified grace period. The kubelet does not evict pods until the
grace period is exceeded. The kubelet returns an error on startup if there is no
specified grace period.
You can specify both a soft eviction threshold grace period and a maximum
allowed pod termination grace period for kubelet to use during evictions. If you
specify a maximum allowed grace period and the soft eviction threshold is met,
the kubelet uses the lesser of the two grace periods. If you do not specify a
maximum allowed grace period, the kubelet kills evicted pods immediately without
graceful termination.
You can use the following flags to configure soft eviction thresholds:
eviction-soft: A set of eviction thresholds like memory.available<1.5Gi
that can trigger pod eviction if held over the specified grace period.
eviction-soft-grace-period: A set of eviction grace periods like memory.available=1m30s
that define how long a soft eviction threshold must hold before triggering a Pod eviction.
eviction-max-pod-grace-period: The maximum allowed grace period (in seconds)
to use when terminating pods in response to a soft eviction threshold being met.
Hard eviction thresholds
A hard eviction threshold has no grace period. When a hard eviction threshold is
met, the kubelet kills pods immediately without graceful termination to reclaim
the starved resource.
You can use the eviction-hard flag to configure a set of hard eviction
thresholds like memory.available<1Gi.
The kubelet has the following default hard eviction thresholds:
memory.available<100Mi
nodefs.available<10%
imagefs.available<15%
nodefs.inodesFree<5% (Linux nodes)
Eviction monitoring interval
The kubelet evaluates eviction thresholds based on its configured housekeeping-interval
which defaults to 10s.
Node conditions
The kubelet reports node conditions to reflect that the node is under pressure
because hard or soft eviction threshold is met, independent of configured grace
periods.
The kubelet maps eviction signals to node conditions as follows:
Node Condition
Eviction Signal
Description
MemoryPressure
memory.available
Available memory on the node has satisfied an eviction threshold
DiskPressure
nodefs.available, nodefs.inodesFree, imagefs.available, or imagefs.inodesFree
Available disk space and inodes on either the node's root filesystem or image filesystem has satisfied an eviction threshold
PIDPressure
pid.available
Available processes identifiers on the (Linux) node has fallen below an eviction threshold
The kubelet updates the node conditions based on the configured
--node-status-update-frequency, which defaults to 10s.
Node condition oscillation
In some cases, nodes oscillate above and below soft eviction thresholds without
holding for the defined grace periods. This causes the reported node condition
to constantly switch between true and false, leading to bad eviction decisions.
To protect against oscillation, you can use the eviction-pressure-transition-period
flag, which controls how long the kubelet must wait before transitioning a node
condition to a different state. The transition period has a default value of 5m.
Reclaiming node level resources
The kubelet tries to reclaim node-level resources before it evicts end-user pods.
When a DiskPressure node condition is reported, the kubelet reclaims node-level
resources based on the filesystems on the node.
With imagefs
If the node has a dedicated imagefs filesystem for container runtimes to use,
the kubelet does the following:
If the nodefs filesystem meets the eviction thresholds, the kubelet garbage collects
dead pods and containers.
If the imagefs filesystem meets the eviction thresholds, the kubelet
deletes all unused images.
Without imagefs
If the node only has a nodefs filesystem that meets eviction thresholds,
the kubelet frees up disk space in the following order:
Garbage collect dead pods and containers
Delete unused images
Pod selection for kubelet eviction
If the kubelet's attempts to reclaim node-level resources don't bring the eviction
signal below the threshold, the kubelet begins to evict end-user pods.
The kubelet uses the following parameters to determine pod eviction order:
As a result, kubelet ranks and evicts pods in the following order:
BestEffort or Burstable pods where the usage exceeds requests. These pods
are evicted based on their Priority and then by how much their usage level
exceeds the request.
Guaranteed pods and Burstable pods where the usage is less than requests
are evicted last, based on their Priority.
Note: The kubelet does not use the pod's QoS class to determine the eviction order.
You can use the QoS class to estimate the most likely pod eviction order when
reclaiming resources like memory. QoS does not apply to EphemeralStorage requests,
so the above scenario will not apply if the node is, for example, under DiskPressure.
Guaranteed pods are guaranteed only when requests and limits are specified for
all the containers and they are equal. These pods will never be evicted because
of another pod's resource consumption. If a system daemon (such as kubelet,
docker, and journald) is consuming more resources than were reserved via
system-reserved or kube-reserved allocations, and the node only has
Guaranteed or Burstable pods using less resources than requests left on it,
then the kubelet must choose to evict one of these pods to preserve node stability
and to limit the impact of resource starvation on other pods. In this case, it
will choose to evict pods of lowest Priority first.
When the kubelet evicts pods in response to inode or PID starvation, it uses
the Priority to determine the eviction order, because inodes and PIDs have no
requests.
The kubelet sorts pods differently based on whether the node has a dedicated
imagefs filesystem:
With imagefs
If nodefs is triggering evictions, the kubelet sorts pods based on nodefs
usage (local volumes + logs of all containers).
If imagefs is triggering evictions, the kubelet sorts pods based on the
writable layer usage of all containers.
Without imagefs
If nodefs is triggering evictions, the kubelet sorts pods based on their total
disk usage (local volumes + logs & writable layer of all containers)
Minimum eviction reclaim
In some cases, pod eviction only reclaims a small amount of the starved resource.
This can lead to the kubelet repeatedly hitting the configured eviction thresholds
and triggering multiple evictions.
You can use the --eviction-minimum-reclaim flag or a kubelet config file
to configure a minimum reclaim amount for each resource. When the kubelet notices
that a resource is starved, it continues to reclaim that resource until it
reclaims the quantity you specify.
For example, the following configuration sets minimum reclaim amounts:
In this example, if the nodefs.available signal meets the eviction threshold,
the kubelet reclaims the resource until the signal reaches the threshold of 1Gi,
and then continues to reclaim the minimum amount of 500Mi it until the signal
reaches 1.5Gi.
Similarly, the kubelet reclaims the imagefs resource until the imagefs.available
signal reaches 102Gi.
The default eviction-minimum-reclaim is 0 for all resources.
Node out of memory behavior
If the node experiences an out of memory (OOM) event prior to the kubelet
being able to reclaim memory, the node depends on the oom_killer
to respond.
The kubelet sets an oom_score_adj value for each container based on the QoS for the pod.
Note: The kubelet also sets an oom_score_adj value of -997 for containers in Pods that have
system-node-criticalPriority
If the kubelet can't reclaim memory before a node experiences OOM, the
oom_killer calculates an oom_score based on the percentage of memory it's
using on the node, and then adds the oom_score_adj to get an effective oom_score
for each container. It then kills the container with the highest score.
This means that containers in low QoS pods that consume a large amount of memory
relative to their scheduling requests are killed first.
Unlike pod eviction, if a container is OOM killed, the kubelet can restart it
based on its RestartPolicy.
Best practices
The following sections describe best practices for eviction configuration.
Schedulable resources and eviction policies
When you configure the kubelet with an eviction policy, you should make sure that
the scheduler will not schedule pods if they will trigger eviction because they
immediately induce memory pressure.
Consider the following scenario:
Node memory capacity: 10Gi
Operator wants to reserve 10% of memory capacity for system daemons (kernel, kubelet, etc.)
Operator wants to evict Pods at 95% memory utilization to reduce incidence of system OOM.
For this to work, the kubelet is launched as follows:
In this configuration, the --system-reserved flag reserves 1.5Gi of memory
for the system, which is 10% of the total memory + the eviction threshold amount.
The node can reach the eviction threshold if a pod is using more than its request,
or if the system is using more than 1Gi of memory, which makes the memory.available
signal fall below 500Mi and triggers the threshold.
DaemonSet
Pod Priority is a major factor in making eviction decisions. If you do not want
the kubelet to evict pods that belong to a DaemonSet, give those pods a high
enough priorityClass in the pod spec. You can also use a lower priorityClass
or the default to only allow DaemonSet pods to run when there are enough
resources.
Known issues
The following sections describe known issues related to out of resource handling.
kubelet may not observe memory pressure right away
By default, the kubelet polls cAdvisor to collect memory usage stats at a
regular interval. If memory usage increases within that window rapidly, the
kubelet may not observe MemoryPressure fast enough, and the OOMKiller
will still be invoked.
You can use the --kernel-memcg-notification flag to enable the memcg
notification API on the kubelet to get notified immediately when a threshold
is crossed.
If you are not trying to achieve extreme utilization, but a sensible measure of
overcommit, a viable workaround for this issue is to use the --kube-reserved
and --system-reserved flags to allocate memory for the system.
active_file memory is not considered as available memory
On Linux, the kernel tracks the number of bytes of file-backed memory on active
LRU list as the active_file statistic. The kubelet treats active_file memory
areas as not reclaimable. For workloads that make intensive use of block-backed
local storage, including ephemeral local storage, kernel-level caches of file
and block data means that many recently accessed cache pages are likely to be
counted as active_file. If enough of these kernel block buffers are on the
active LRU list, the kubelet is liable to observe this as high resource use and
taint the node as experiencing memory pressure - triggering pod eviction.
You can work around that behavior by setting the memory limit and memory request
the same for containers likely to perform intensive I/O activity. You will need
to estimate or measure an optimal memory limit value for that container.
API-initiated eviction is the process by which you use the Eviction API
to create an Eviction object that triggers graceful pod termination.
You can request eviction by directly calling the Eviction API
using a client of the kube-apiserver, like the kubectl drain command.
This creates an Eviction object, which causes the API server to terminate the Pod.
The kube-scheduler can be configured to enable bin packing of resources along
with extended resources using RequestedToCapacityRatioResourceAllocation
priority function. Priority functions can be used to fine-tune the
kube-scheduler as per custom needs.
Enabling Bin Packing using RequestedToCapacityRatioResourceAllocation
Kubernetes allows the users to specify the resources along with weights for
each resource to score nodes based on the request to capacity ratio. This
allows users to bin pack extended resources by using appropriate parameters
and improves the utilization of scarce resources in large clusters. The
behavior of the RequestedToCapacityRatioResourceAllocation priority function
can be controlled by a configuration option called RequestedToCapacityRatioArgs.
This argument consists of two parameters shape and resources. The shape
parameter allows the user to tune the function as least requested or most
requested based on utilization and score values. The resources parameter
consists of name of the resource to be considered during scoring and weight
specify the weight of each resource.
Below is an example configuration that sets
requestedToCapacityRatioArguments to bin packing behavior for extended
resources intel.com/foo and intel.com/bar.
Referencing the KubeSchedulerConfiguration file with the kube-scheduler
flag --config=/path/to/config/file will pass the configuration to the
scheduler.
This feature is disabled by default
Tuning the Priority Function
shape is used to specify the behavior of the
RequestedToCapacityRatioPriority function.
The above arguments give the node a score of 0 if utilization is 0% and 10 for
utilization 100%, thus enabling bin packing behavior. To enable least
requested the score value must be reversed as follows.
The weight parameter is optional and is set to 1 if not specified. Also, the
weight cannot be set to a negative value.
Node scoring for capacity allocation
This section is intended for those who want to understand the internal details
of this feature.
Below is an example of how the node score is calculated for a given set of values.
The scheduling framework is a pluggable architecture for the Kubernetes scheduler.
It adds a new set of "plugin" APIs to the existing scheduler. Plugins are compiled into the scheduler. The APIs allow most scheduling features to be implemented as plugins, while keeping the
scheduling "core" lightweight and maintainable. Refer to the design proposal of the
scheduling framework for more technical information on the design of the
framework.
Framework workflow
The Scheduling Framework defines a few extension points. Scheduler plugins
register to be invoked at one or more extension points. Some of these plugins
can change the scheduling decisions and some are informational only.
Each attempt to schedule one Pod is split into two phases, the scheduling
cycle and the binding cycle.
Scheduling Cycle & Binding Cycle
The scheduling cycle selects a node for the Pod, and the binding cycle applies
that decision to the cluster. Together, a scheduling cycle and binding cycle are
referred to as a "scheduling context".
Scheduling cycles are run serially, while binding cycles may run concurrently.
A scheduling or binding cycle can be aborted if the Pod is determined to
be unschedulable or if there is an internal error. The Pod will be returned to
the queue and retried.
Extension points
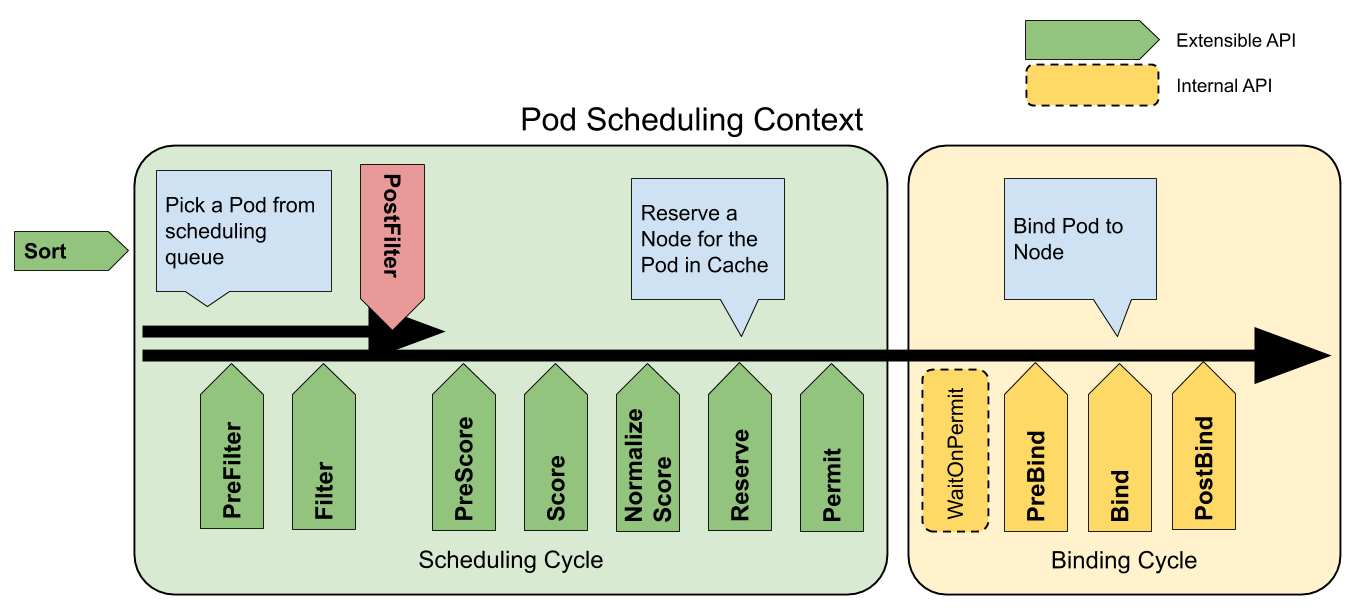
The following picture shows the scheduling context of a Pod and the extension
points that the scheduling framework exposes. In this picture "Filter" is
equivalent to "Predicate" and "Scoring" is equivalent to "Priority function".
One plugin may register at multiple extension points to perform more complex or
stateful tasks.
scheduling framework extension points
QueueSort
These plugins are used to sort Pods in the scheduling queue. A queue sort plugin
essentially provides a Less(Pod1, Pod2) function. Only one queue sort
plugin may be enabled at a time.
PreFilter
These plugins are used to pre-process info about the Pod, or to check certain
conditions that the cluster or the Pod must meet. If a PreFilter plugin returns
an error, the scheduling cycle is aborted.
Filter
These plugins are used to filter out nodes that cannot run the Pod. For each
node, the scheduler will call filter plugins in their configured order. If any
filter plugin marks the node as infeasible, the remaining plugins will not be
called for that node. Nodes may be evaluated concurrently.
PostFilter
These plugins are called after Filter phase, but only when no feasible nodes
were found for the pod. Plugins are called in their configured order. If
any postFilter plugin marks the node as Schedulable, the remaining plugins
will not be called. A typical PostFilter implementation is preemption, which
tries to make the pod schedulable by preempting other Pods.
PreScore
These plugins are used to perform "pre-scoring" work, which generates a sharable
state for Score plugins to use. If a PreScore plugin returns an error, the
scheduling cycle is aborted.
Score
These plugins are used to rank nodes that have passed the filtering phase. The
scheduler will call each scoring plugin for each node. There will be a well
defined range of integers representing the minimum and maximum scores. After the
NormalizeScore phase, the scheduler will combine node
scores from all plugins according to the configured plugin weights.
NormalizeScore
These plugins are used to modify scores before the scheduler computes a final
ranking of Nodes. A plugin that registers for this extension point will be
called with the Score results from the same plugin. This is called
once per plugin per scheduling cycle.
For example, suppose a plugin BlinkingLightScorer ranks Nodes based on how
many blinking lights they have.
funcScoreNode(_ *v1.pod, n *v1.Node) (int, error) {
returngetBlinkingLightCount(n)
}
However, the maximum count of blinking lights may be small compared to
NodeScoreMax. To fix this, BlinkingLightScorer should also register for this
extension point.
If any NormalizeScore plugin returns an error, the scheduling cycle is
aborted.
Note: Plugins wishing to perform "pre-reserve" work should use the
NormalizeScore extension point.
Reserve
A plugin that implements the Reserve extension has two methods, namely Reserve
and Unreserve, that back two informational scheduling phases called Reserve
and Unreserve, respectively. Plugins which maintain runtime state (aka "stateful
plugins") should use these phases to be notified by the scheduler when resources
on a node are being reserved and unreserved for a given Pod.
The Reserve phase happens before the scheduler actually binds a Pod to its
designated node. It exists to prevent race conditions while the scheduler waits
for the bind to succeed. The Reserve method of each Reserve plugin may succeed
or fail; if one Reserve method call fails, subsequent plugins are not executed
and the Reserve phase is considered to have failed. If the Reserve method of
all plugins succeed, the Reserve phase is considered to be successful and the
rest of the scheduling cycle and the binding cycle are executed.
The Unreserve phase is triggered if the Reserve phase or a later phase fails.
When this happens, the Unreserve method of all Reserve plugins will be
executed in the reverse order of Reserve method calls. This phase exists to
clean up the state associated with the reserved Pod.
Caution: The implementation of the Unreserve method in Reserve plugins must be
idempotent and may not fail.
Permit
Permit plugins are invoked at the end of the scheduling cycle for each Pod, to
prevent or delay the binding to the candidate node. A permit plugin can do one of
the three things:
approve Once all Permit plugins approve a Pod, it is sent for binding.
deny If any Permit plugin denies a Pod, it is returned to the scheduling queue.
This will trigger the Unreserve phase in Reserve plugins.
wait (with a timeout) If a Permit plugin returns "wait", then the Pod is kept in an internal "waiting"
Pods list, and the binding cycle of this Pod starts but directly blocks until it
gets approved. If a timeout occurs, wait becomes deny
and the Pod is returned to the scheduling queue, triggering the
Unreserve phase in Reserve plugins.
Note: While any plugin can access the list of "waiting" Pods and approve them
(see FrameworkHandle), we expect only the permit
plugins to approve binding of reserved Pods that are in "waiting" state. Once a Pod
is approved, it is sent to the PreBind phase.
PreBind
These plugins are used to perform any work required before a Pod is bound. For
example, a pre-bind plugin may provision a network volume and mount it on the
target node before allowing the Pod to run there.
If any PreBind plugin returns an error, the Pod is rejected and
returned to the scheduling queue.
Bind
These plugins are used to bind a Pod to a Node. Bind plugins will not be called
until all PreBind plugins have completed. Each bind plugin is called in the
configured order. A bind plugin may choose whether or not to handle the given
Pod. If a bind plugin chooses to handle a Pod, the remaining bind plugins are
skipped.
PostBind
This is an informational extension point. Post-bind plugins are called after a
Pod is successfully bound. This is the end of a binding cycle, and can be used
to clean up associated resources.
Plugin API
There are two steps to the plugin API. First, plugins must register and get
configured, then they use the extension point interfaces. Extension point
interfaces have the following form.
type Plugin interface {
Name() string
}
type QueueSortPlugin interface {
Plugin
Less(*v1.pod, *v1.pod) bool
}
type PreFilterPlugin interface {
Plugin
PreFilter(context.Context, *framework.CycleState, *v1.pod) error
}
// ...
Plugin configuration
You can enable or disable plugins in the scheduler configuration. If you are using
Kubernetes v1.18 or later, most scheduling
plugins are in use and
enabled by default.
In addition to default plugins, you can also implement your own scheduling
plugins and get them configured along with default plugins. You can visit
scheduler-plugins for more details.
If you are using Kubernetes v1.18 or later, you can configure a set of plugins as
a scheduler profile and then define multiple profiles to fit various kinds of workload.
Learn more at multiple profiles.
10 - Scheduler Performance Tuning
FEATURE STATE:Kubernetes v1.14 [beta]
kube-scheduler
is the Kubernetes default scheduler. It is responsible for placement of Pods
on Nodes in a cluster.
Nodes in a cluster that meet the scheduling requirements of a Pod are
called feasible Nodes for the Pod. The scheduler finds feasible Nodes
for a Pod and then runs a set of functions to score the feasible Nodes,
picking a Node with the highest score among the feasible ones to run
the Pod. The scheduler then notifies the API server about this decision
in a process called Binding.
This page explains performance tuning optimizations that are relevant for
large Kubernetes clusters.
In large clusters, you can tune the scheduler's behaviour balancing
scheduling outcomes between latency (new Pods are placed quickly) and
accuracy (the scheduler rarely makes poor placement decisions).
You configure this tuning setting via kube-scheduler setting
percentageOfNodesToScore. This KubeSchedulerConfiguration setting determines
a threshold for scheduling nodes in your cluster.
Setting the threshold
The percentageOfNodesToScore option accepts whole numeric values between 0
and 100. The value 0 is a special number which indicates that the kube-scheduler
should use its compiled-in default.
If you set percentageOfNodesToScore above 100, kube-scheduler acts as if you
had set a value of 100.
To change the value, edit the
kube-scheduler configuration file
and then restart the scheduler.
In many cases, the configuration file can be found at /etc/kubernetes/config/kube-scheduler.yaml.
After you have made this change, you can run
kubectl get pods -n kube-system | grep kube-scheduler
to verify that the kube-scheduler component is healthy.
Node scoring threshold
To improve scheduling performance, the kube-scheduler can stop looking for
feasible nodes once it has found enough of them. In large clusters, this saves
time compared to a naive approach that would consider every node.
You specify a threshold for how many nodes are enough, as a whole number percentage
of all the nodes in your cluster. The kube-scheduler converts this into an
integer number of nodes. During scheduling, if the kube-scheduler has identified
enough feasible nodes to exceed the configured percentage, the kube-scheduler
stops searching for more feasible nodes and moves on to the
scoring phase.
If you don't specify a threshold, Kubernetes calculates a figure using a
linear formula that yields 50% for a 100-node cluster and yields 10%
for a 5000-node cluster. The lower bound for the automatic value is 5%.
This means that, the kube-scheduler always scores at least 5% of your cluster no
matter how large the cluster is, unless you have explicitly set
percentageOfNodesToScore to be smaller than 5.
If you want the scheduler to score all nodes in your cluster, set
percentageOfNodesToScore to 100.
Example
Below is an example configuration that sets percentageOfNodesToScore to 50%.
percentageOfNodesToScore must be a value between 1 and 100 with the default
value being calculated based on the cluster size. There is also a hardcoded
minimum value of 50 nodes.
Note:
In clusters with less than 50 feasible nodes, the scheduler still
checks all the nodes because there are not enough feasible nodes to stop
the scheduler's search early.
In a small cluster, if you set a low value for percentageOfNodesToScore, your
change will have no or little effect, for a similar reason.
If your cluster has several hundred Nodes or fewer, leave this configuration option
at its default value. Making changes is unlikely to improve the
scheduler's performance significantly.
An important detail to consider when setting this value is that when a smaller
number of nodes in a cluster are checked for feasibility, some nodes are not
sent to be scored for a given Pod. As a result, a Node which could possibly
score a higher value for running the given Pod might not even be passed to the
scoring phase. This would result in a less than ideal placement of the Pod.
You should avoid setting percentageOfNodesToScore very low so that kube-scheduler
does not make frequent, poor Pod placement decisions. Avoid setting the
percentage to anything below 10%, unless the scheduler's throughput is critical
for your application and the score of nodes is not important. In other words, you
prefer to run the Pod on any Node as long as it is feasible.
How the scheduler iterates over Nodes
This section is intended for those who want to understand the internal details
of this feature.
In order to give all the Nodes in a cluster a fair chance of being considered
for running Pods, the scheduler iterates over the nodes in a round robin
fashion. You can imagine that Nodes are in an array. The scheduler starts from
the start of the array and checks feasibility of the nodes until it finds enough
Nodes as specified by percentageOfNodesToScore. For the next Pod, the
scheduler continues from the point in the Node array that it stopped at when
checking feasibility of Nodes for the previous Pod.
If Nodes are in multiple zones, the scheduler iterates over Nodes in various
zones to ensure that Nodes from different zones are considered in the
feasibility checks. As an example, consider six nodes in two zones:
Zone 1: Node 1, Node 2, Node 3, Node 4
Zone 2: Node 5, Node 6
The Scheduler evaluates feasibility of the nodes in this order:
Node 1, Node 5, Node 2, Node 6, Node 3, Node 4
After going over all the Nodes, it goes back to Node 1.